Without BuildKit's secrets,
ARG USERNAME=webinative
ARG USER_UID=1000
ARG USER_GID=${USER_UID}
# create user
RUN groupadd --gid $USER_GID ${USERNAME} \
&& useradd --uid ${USER_UID} --gid ${USER_GID} -m ${USERNAME}
TIL about BuildKit in Docker.
As of today, the legacy builder is the default option. However, BuildKit can be enabled with the simple ENV variable,
DOCKER_BUILDKIT=1 docker build
Exhibit AI output with LangChain AgentExecutor with tools.
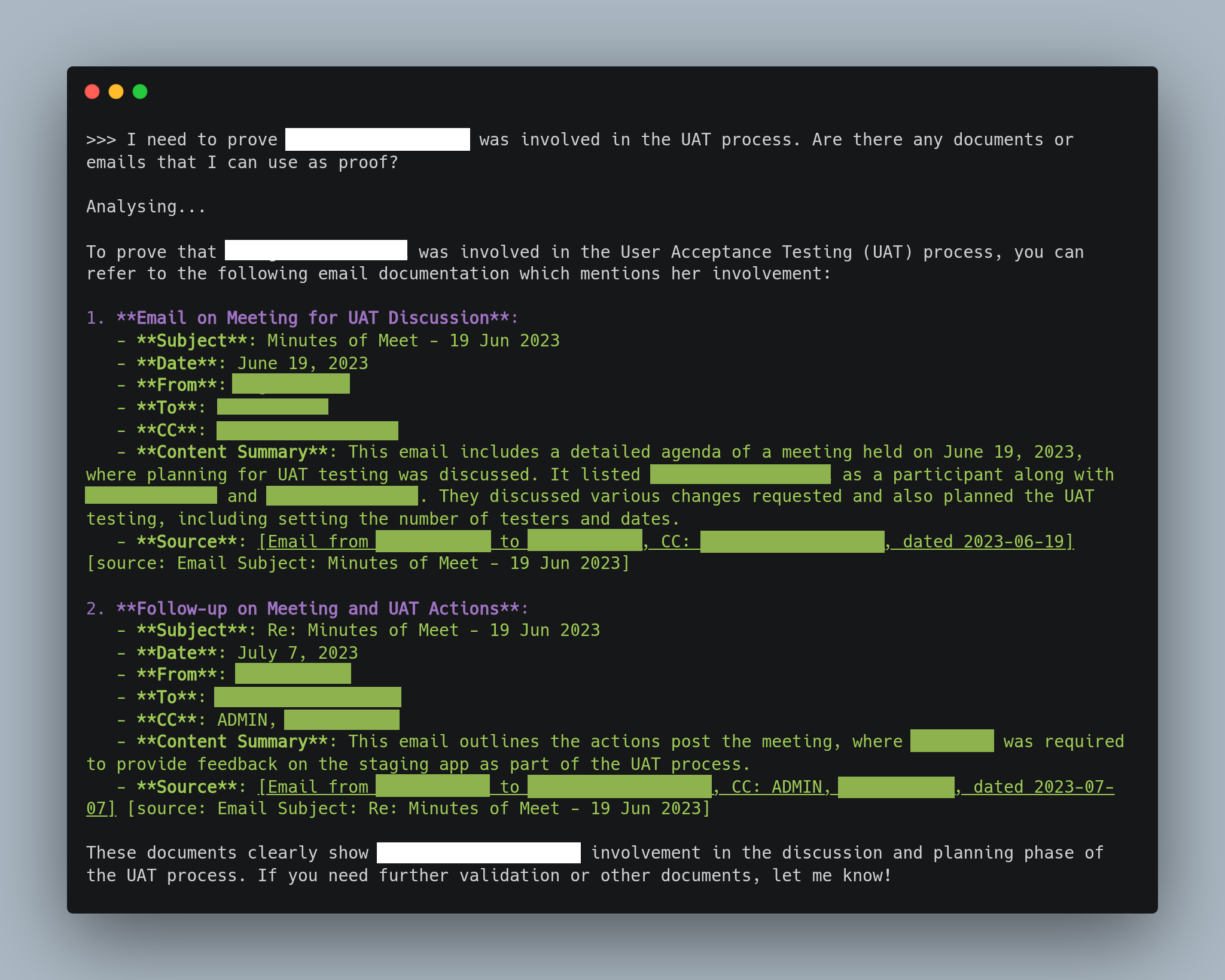
Been refining Exhibit AI with LangChain tools.
- Chat history now preserves both user + AI turns
- Smarter prompt design keeps case context intact
- More reliable, context-aware insights for lawyers
Status update on the Exhibit AI POC: LinkedIn post
Progressing briskly on Exhibit AI.
Put together a CLI tool and ran a few queries on documents from an actual legal dispute. Happy with the response.
Just letting it slide. Deleted the A record and should be fine now.
Our platform is open source so we keep everything open. And what are your devs doing?
I had a good laugh.
I'm wondering if this site is for scamming people. Should I scam the scammer? Add more DNS records to point their way?
So, I checked their website. The landing page talks about decentralized revolution and network security. Yet, they couldn't implement a simple domain name check.
I pointed this out to him and the reply was EPIC.